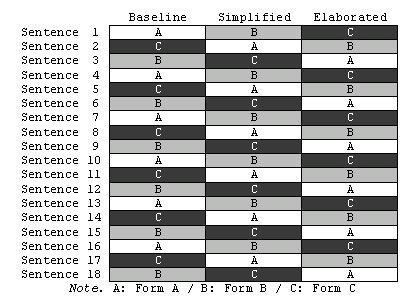
Figure 3. Test Forms.
Since no one would deny the necessity of input comprehension for second language acquisition (SLA), it is of theoretical and empirical interest to inquire how input is made comprehensible to L2 learners with limited proficiency. Motivated by studies in caretaker speech in first language acquisition, SLA researchers have investigated native speakers' (NSs') input adjustments toward L2 learners. Input targeted to L2 learners is often called "foreigner talk" (Ferguson, 1975), or "teacher talk" in the classroom situation (Chaudron, 1988), and research has revealed that input to non-native speakers (NNSs) is adjusted, or modified, in various ways.
When one discusses the role of input modification, it is useful to keep in mind two different criteria that can be paraphrased into two questions: (a) What is modified? (target of modification); and (b) How is it modified? (type of modification). With regard to the first question, studies have investigated modifications at different linguistic levels, i.e., phonology, lexicon, syntax, and discourse (Chaudron, 1988). To name a few examples, NSs are found to speak more slowly to NNSs with longer pauses (Wesche & Ready, 1985, phonological modification), and speak in shorter utterances to lower proficiency learners (Kleifgen, 1985, syntactic modification). Modification at the discourse level is also referred to as interactional modification, and forms an independent area of SLA research (e.g., Pica, Doughty, & Young, 1986; Pica, Young, & Doughty, [-- 1 --] 1987).
The other question, How is input modified?, can be addressed to modifications of lexicon and syntax. There are two types of modifications: (a) simplification, and (b) elaboration. Simplification has widely been used in many commercially published L2 reading materials under the belief that the use of controlled vocabularies and short simple sentences will facilitate L2 reading comprehension. Most of the readability formulas are also based on the lexical and syntactic complexity, such as ratio of low-frequency words or sentence lengths (Baker, Atwood, & Duffy, 1988). Though simplified texts are generally easier to understand (Yano, Long, & Ross, 1994), some researchers argue against the use of simplification. In first language (L1) reading research, Green & Olsen (1988) found that readability-adapted (i.e., simplified) materials were not significantly easier for children to understand than the originals. In L2 reading study, Blau (1982) demonstrated that simple sentences only do not necessarily aid comprehension.
In terms of language learning, even if simplification may facilitate L2 comprehension, it has a crucial weakness in that comprehension is achieved by removing items that L2 learners need to learn. To quote Yano et al. (1994):
Studies have examined the effects of text modification on L2 comprehension since the early '80s (there had been 15 studies by 1995, according to Chung, 1995). Yano et al. (1994), in their review of the literature, summarized the results of those studies into six general findings:
(pp. 195-200)
Generally speaking, text modifications seem to have positive effects on L2 comprehension. However, we are not yet confident enough to emphasize their importance for the following reasons. First, it is obvious that more research is needed along this line to better understand the role of text modifications. As Yano et al. (1994) suggest, we are still in need of "a larger, more carefully controlled study of the relative effectiveness of simplification and elaboration" (p. 200). The second reason is related to this claim. Few studies have demonstrated a clear-cut effect of a single type of modification. What previous studies have found was that a combination of a few different types of modifications tend to facilitate L2 comprehension. One possible reason for these rather weak findings is that the comprehension measures used in these [-- 3 --] studies were not sensitive enough to differentiate levels of comprehension achieved by different types of modifications. Most of the studies except Pica et al. (1986, 1987) used multiple-choice questions (either during or after the listening/reading task), recall, cloze, and/or dictation as their measures of comprehension. These measures can do no more than indicate whether or not L2 learners clearly understand (part of) the passage. In other words, it may be the case that the results of previous studies are less straightforward not because text modifications did not work well but because their effects were so subtle that they could not be detected by those comprehension measures.To solve this problem, I propose the use of reaction time as a measure of L2 comprehension. Reaction time (RT) has been developed as a supplemental measure to grammaticality judgement used in psycholinguistic studies under the UG paradigm (Bley-Vroman & Masterson, 1989). Freedman & Forster (1985) set up a sentence matching task (i.e., the task to find if two sentences are identical or not), and demonstrated that the matching task took longer when the sentences were ungrammatical. RT is also used in L1 reading studies, referred to as reading time. Kemper (1988), for example, found that the mean reading times for the target sentences were significantly longer with passages in which some sentences referring to critical actions, physical states, or mental states were deleted.
It is assumed that, in a text modification study, mean reading time becomes shorter when a certain type of modification facilitates L2 comprehension. Since this measure is a ratio scale rather than nominal (i.e., correct/wrong) as other measures used in previous studies, it is expected to successfully distinguish the levels of comprehensibility. However, this method also has a restriction, too. Since RT is a sensitive measure, careful attention should be paid to control all factors other than text modification. To do this, I decided to test L2 comprehension at the sentence level, rather than the whole passage. By comparing sentences that are modified versions of the same sentence, the [-- 4 --] influence of unwanted variables can be minimized, if not completely eliminated.
The purpose of this study is to investigate the relative effects of text simplification and elaboration on L2 comprehension. This will be achieved by measuring the mean reading times of sentences with different modifications.
LEXICAL MODIFICATION
Lexical modification was chosen for this study for the following two reasons. First, several studies have investigated the relationship between text modifications and vocabulary acquisition (e.g., Watanabe, 1992; Chung, 1995; Kim, 1996). Although these researchers had slightly different interests, they all tested the effects of text modification on vocabulary acquisition as part of their studies. Although the results generally suggest positive effects of text modification on vocabulary acquisition, a significant difference was found only by Kim (1996). Thus, there is still a room for a new study along this line.
The second reason is a practical one. It is difficult to test the effects of syntactic modification at the sentence level. It seems, at least to me, impossible to create a comparable pair of a syntactically simplified sentence and an elaborated one. Sentences can be syntactically simplified in some cases, e.g., by using the canonical word order, and then the comprehensibility of simplified sentences can be compared with that of the baseline NS sentences (e.g., Issidorides & Hulstijn, 1992), but there seems to be no syntactically elaborated sentence that can be compared with the simplified version. On the other hand, sentences can be lexically simplified and elaborated with relative ease. In a simplified version, low-frequency vocabulary items can be replaced by high-frequency synonyms, for example. To lexically elaborate a sentence, high-frequency [-- 5 --] synonyms can be attached in apposition to the low-frequency words.
Lexical simplification in this study is more specific than that of the earlier studies (e.g., Parker & Chaudron, 1987). It is defined as substituting unknown words with high-frequency "basic" vocabulary items (an "unknown word" will be operationally defined later). Lexical elaboration, on the other hand, is achieved not by deleting those unknown words, but by adding their definitions, synonyms, antonyms, or hyperonyms in apposition to them (see Figure 1).
Baseline:Everybody knows that Ken is diligent and kind to others.
Simplified:Everybody knows that Ken is hardworking and kind to others.
Elaborated:Everybody knows that Ken is diligent, or hardworking, and kind to others.
Figure 1. Samples of Lexical Modification.
RESEARCH QUESTIONS
Two research questions immerged from the literature review:
[-- 6 --]
METHOD
Participants
Six low-intermediate learners of English (one female and five male) at an ESL program in Hawai'i volunteered for this study. Four of them were native speakers of Japanese and the other two spoke Korean as their first language. Their mean age was 25.83 with the range between 23 and 31. All of the participants except one have taken TOEFL at least once, and their most recent scores ranged from 450 to 525 with the mean score of 488.4. They all have had formal English language education in their home countries at the high school level. Their length of stay in English-speaking countries ranged from two months to twelve months with a mean of 7.33 months (for more detailed bio-data, see Appendix A). Since the participants were recruited on a voluntary basis, and the sample size was rather small, it would be difficult to generalize the findings of this study. The results will be, however, a valuable source of information for further revisions of the research.
Materials
Test Sentences
First of all, 18 very low-frequency words were selected from a well-known frequency list of words in spoken American English (Dahl, 1979). In the corpus of 1,058,888 tokens and 17,871 types by Dahl (1979), the 18 words were picked only from those whose frequency counts were one or two, i.e., words that are ranked in 8,121 or below in the descending order. The next step was to prepare substitutes for these 18 words. Synonyms were used whenever available, and hyperonyms and definitions were also used. All the words used for substitutes were within the 2000-word Longman Defining Vocabulary (Longman, 1987). Also, it was confirmed that none of the target [-- 7 --] words were in the 2000 defining vocabulary. The target words and their substitutes are listed in Figure 2.
------------------------------------- target words substitutes ------------------------------------- altitude height beast animal blunt not sharp cease stop chuckle laugh cottage small house damp wet detect notice diligent hardworking finch bird horrid unkind mumble speak unclearly punctual always on time purchase buy purse handbag sob cry vendor seller weep cry -------------------------------------Figure 2. Target Words and Their Substitutes (in alphabetical order)
Eighteen sentences were created by the author in such a way that one target word was included in each sentence. Attention was paid not to include low-frequency words in the sentences except for the target words. After creating the sentences, the Longman list was used again to make sure that all the words except for the target words in these sentences were made up of the words in the list. Simplified and elaborated versions of these 18 baseline sentences were then created. All the sentences were screened by a native speaker of English for their naturalness (for the complete list of the test sentences, see Appendix B). Table 1 shows the mean lengths and standard deviations of test [-- 8 --] sentences. As you can see, elaborated sentences are about two words longer than the other types of sentences. Therefore, mean reading time per word, not the raw reading time, was calculated to compare the comprehension of the three versions of sentences.
Table 1. Mean Sentence Length (word)
---------------------------------------- Condition M SD n ---------------------------------------- Baseline 11.22 2.32 18 Simplified 11.50 2.06 18 Elaborated 13.50 2.06 18 ----------------------------------------
Vocabulary Tests
Two vocabulary tests were created for this study: the form recognition test and the word translation test. A form recognition test was administered since the first stage of language acquisition is considered to be recognition of target form (Chaudron, 1985). The participants were given 36 words, including 18 target words, and were asked to circle the words they thought they had seen in the test sentences. The order of the 36 words were randomized (see Appendix C).
The other vocabulary test, the word translation test, can measure a deeper level of vocabulary acquisition (see Appendix D). Since this is a pilot study, two vocabulary tests were administered to investigate what level of learning, if any, took place during the treatment. All the 18 target words were randomly listed, and the participants were asked to translate them into their L1 (i.e., Japanese or Korean).
Procedures
The experiment took place in one session at a computer lab equipped with Macintosh computers at the University of Hawai'i at Manoa. The lab was reserved for this experiment, and therefore no other people were allowed to enter during the experiment.
[-- 9 --]
The first session of the experiment was administered on Macintosh computers using PsyScope, a graphic user interface (GUI) program designed for psychological experiments (Cohen, MacWhinney, Flatt, & Provost, 1993). This session served as the treatment (i.e., reading test sentences), and the participants' comprehension was also measured by their mean reading times per word. First, a set of instructions and example sentences were displayed on the screen, then a trial item, then the actual test instrument. The participants were encouraged to ask questions before the actual test. A given test item is presented as follows:
After this PsyScope session, two vocabulary tests were administered.
Design and Analyses
The experiment was designed so that all the other variables could be minimized. First of all, a repeated-measures design was selected to eliminate individual differences. [-- 10 --] In other words, each participant read sentences in all three conditions (i.e., baseline, simplified, and elaborated). Next, three test forms were created in order to eliminate the differences among sentences, as in Figure 3. In this design, three participants can cover all 54 sentences (18 sentences x 3 types). Since this experiment had six participants, each sentence was read by two of them.
Figure 3. Test Forms.
Below is the summary of the design of this study.
Independent Variable:
The analyses were conducted using the SPSS Graduate Pack 8.0 for Windows (SPSS Inc., 1997). The significance level of this study was set at a < .05. Hence, the significance level of each analysis was a < .0167 (a /3 = .05/3 = .0167).
Hypotheses
Three hypotheses were constructed that correspond to the three dependent variables.
The second hypothesis implies that presentation of the target vocabulary would trigger the first stage of vocabulary acquisition, i.e., the recognition of the word form. Hence it was expected that the scores of the form recognition tests would be high in the baseline and the elaborated conditions. On the other hand, no recognition should take place in the simplified condition since the target words were removed for the sake of comprehension.
Acquisition of word meanings is considered a few steps ahead of the recognition of word forms. Therefore, I expected a difference between the baseline condition and the elaborated condition. Since no care was taken to help the participants figure out the meaning of the target words in the baseline condition, the scores of the meaning recognition test would be lower than those in the elaborated condition, in which some hints for the meaning of the target words, such as synonyms or hyperonyms, were available. If the scores in the baseline condition were any better than those of the simplified condition, it would imply that the participants still acquired the meaning of some words probably by guessing the meaning from the context.
RESULTS
Mean Reading Time per Word
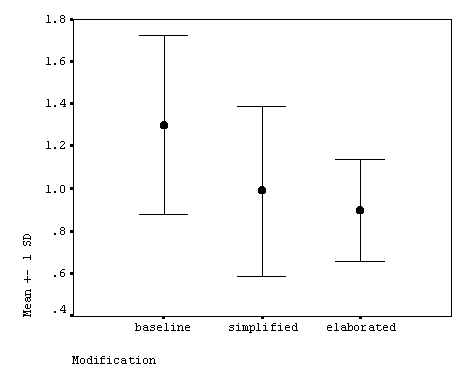
Mean reading times per word are displayed in Table 2 (also see Figure 4). An ANOVA shows a significant difference among the conditions (Table 3). Since a significant difference was found, post hoc multiple comparisons were computed (Table [-- 13 --] 4). A significant difference was found between the baseline and the elaborated conditions, but not between the other pairs. Hypothesis 1 was partially supported.
Table 2. Mean Reading Time per Word (second)
------------------------------------ Condition M SD n ------------------------------------ Baseline 1.302 0.421 6 Simplified 0.990 0.421 6 Ealborated 0.900 0.240 6 ------------------------------------
[-- 14 --]
Table 3. Analysis of Variance for Mean Reading Time per Word
----------------------------------------------------------------- Source SS df MS F p ----------------------------------------------------------------- Condition (A) 0.534 2 0.267 10.488 .004 * Subjects (S) 1.724 5 0.345 A x S 0.255 10 0.025 Total 2.513 17 ----------------------------------------------------------------- * p < .0167
Table 4. Post Hoc Comparisons Table (Paired t-tests with Bonferroni Method)
----------------------------------------------------
Baseline Simplied Elaborated
----------------------------------------------------
Baseline 3.198 ns 5.057 *
Simplified 0.915 ns
----------------------------------------------------
* p < .0056 (= .0167/3)
Form Recognition Test3
Mean scores and standard deviations of the form recognition test are presented in Table 5 (also see Figure 5). An ANOVA shows a significant difference among the conditions (Table 6). Since a significant difference was found, post hoc multiple comparisons were computed (Table 7). Significant differences were found between the simplified condition and the elaborated and the baseline conditions, but not between the baseline condition and the elaborated condition. Hypothesis 2 was, therefore, fully supported.
Table 5. Form Recognition Test
------------------------------------ Condition M SD n ------------------------------------ Baseline 5.000 0.894 6 Simplified 0.833 0.983 6 Ealborated 5.500 0.548 6 ------------------------------------
[-- 15 --]
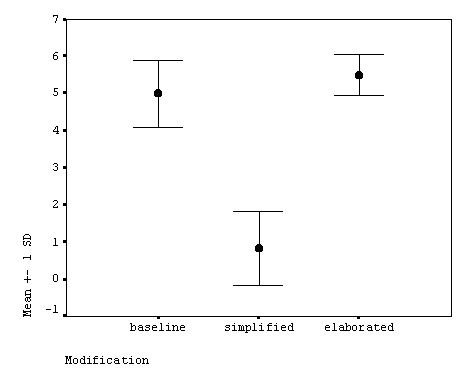
Figure 5. Form Recognition Test
Table 6. Analysis of Variance for Form Recognition Test
----------------------------------------------------------------- Source SS df MS F p ----------------------------------------------------------------- Condition (A) 78.778 2 39.389 66.887 .000 * Subjects (S) 4.444 5 0.889 A x S 5.889 10 0.589 Total 89.111 17 ----------------------------------------------------------------- * p < .0167
Table 7. Post Hoc Comparisons Table (Paired t-tests with Bonferroni Method)
----------------------------------------------------
Baseline Simplied Elaborated
----------------------------------------------------
Baseline 6.934 * -1.464 ns
Simplified -14.000 *
----------------------------------------------------
* p < .0056 (= .0167/3)
[-- 16 --]
Word Translation Test
Mean scores and standard deviations of the word translation test are presented in Figure 6 (also see Table 8). Although mean scores of the elaborated condition are higher than the other two conditions, the difference was not statistically significant (Table 9). Hypothesis 3 was not supported.
Table 8. Word Translation Test
------------------------------------ Condition M SD n ------------------------------------ Baseline 2.000 1.673 6 Simplified 1.333 1.751 6 Ealborated 2.500 1.761 6 ------------------------------------
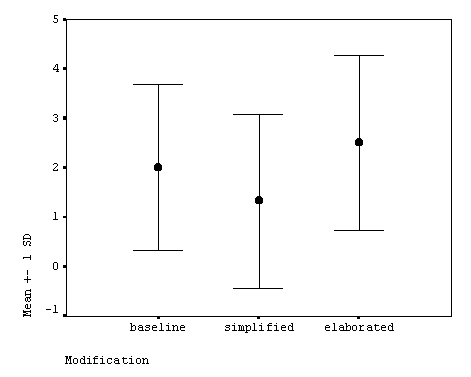
Figure 6.Word Translation Test
[-- 17 --]
Table 9. Analysis of Variance for Word Translation Test
----------------------------------------------------------------- Source SS df MS F p ----------------------------------------------------------------- Condition (A) 4.111 2 2.056 3.491 .071 ns Subjects (S) 38.944 5 7.789 A x S 5.889 10 0.589 Total 48.944 17 -----------------------------------------------------------------
DISCUSSION
In this section, I discuss the results of each dependent variable separately.
Mean Reaction Time per Word
First of all, there was a significant difference among the three conditions (F = 10.488, df = 2/10, p = .004). A measure of the strength of association (eta-squared (h2) = .677) indicates that the relationship between the reading time and lexical modification is fairly strong (i.e., 68% of the variability in the reading time has been accounted for by the three conditions). Post hoc pairwise comparisons revealed that the mean reading time in the elaborated condition was significantly shorter than that in the baseline condition, indicating that lexical elaboration facilitated L2 reading comprehension. On the other hand, although the mean reading time in the simplified condition was shorter than that of the baseline condition, the difference was not statistically significant. The lack of statistical significance, however, does not suggest that they are statistically the same. The difference might have been significant if the n size was larger. Yet this is no more than a speculation, so the result awaits further investigation.
One point needs mentioning here. The results of these analyses should be interpreted with caution. As mentioned earlier, mean reading time was adjusted by the [-- 18 --] length of the sentence (i.e., number of words in the sentence). This presupposes a simple linear relationship between the length of a sentence and reading time (R. Bley-Vroman, personal communication, November 18, 1998). Although another pilot study will be needed to address this issue, it may be safe to conceive that there is some relationship between length and reading time (at least, it takes longer to read a 20-word sentence than a 5-word sentence).
Form Recognition Test
The result of the form recognition test were straightforward. There was a significant difference in scores among the three conditions (F = 66.887, df = 2/10, p = .000). The eta-squared (h2) of .930 indicates a strong relationship between the three conditions and the form recognition scores. Post hoc comparisons detected two significantly different pairs: (a) the mean score of the baseline condition was significantly higher than that of the simplified condition; and (b) the mean score of the elaborated condition was also significantly higher than that of the simplified condition. Therefore, Hypothesis 2 was fully supported. To take a closer look at the test scores, the participants recognized most of the target words in the baseline and the elaborated conditions (the mean scores were 5.000 and 5.500, respectively, at k = 6). This suggests that presentation of unknown vocabulary items can trigger the first step of vocabulary acquisition. The result can be strong support for lexical elaboration rather than simplification. In terms of L2 vocabulary learning, elaboration is favorable since lexical simplification deprives the learners of an opportunity for vocabulary acquisition.
Word Translation Test
Unfortunately, the mean scores of the word translation test among the three conditions were not statistically significant (F = 3.491, df = 2/10, p = .071). I will point [-- 19 --] out three potential reasons for this result. One interpretation is that the small N size (N = 6) might have reduced the effects of lexical modification. The descriptive statistics shows that the mean score of the elaborated condition was the highest (M = 2.500), and that of the simplified the lowest (M = 1.333), which is consistent with my hypothesis. A further study with a larger N size is necessary to draw a conclusion.
An alternative interpretation of the results is that the word translation test was too difficult. Considering the number of the words tested (k = 6), even the highest mean score of the elaborated condition (M = 2.500) was not so high. It can be assumed that one instance of the target word was not sufficient for the deeper level of vocabulary acquisition measured by the word translation test. A different measure of vocabulary acquisition will be needed that can test less than complete learning of a word than the translation test. Chung (1995), for example, used a multiple-choice meaning recognition test. In this test the participants do not need to produce the meaning in their L1 since a list of meanings in their L1 is already presented. This can be an alternative measure of the word translation test.
Thirdly, the mean score of the simplified condition (M = 1.333) suggests that some of the participants already knew some of the target words. It should be noted that the participants did not encounter these target words in the simplified condition. The use of low-frequency words from a large corpus was not successful in determining words that were unknown to the participants. To solve this problem, nonsense words can be used for a further study. By using fake words, one can eliminate the possibility that the participants already know the target words.
[-- 20 --]
CONCLUSION
This study has presented some support for the assumption that lexical modification, or at least lexical elaboration, facilitates L2 reading comprehension. Also, the results confirmed that elaboration is more favorable than simplification in terms of L2 vocabulary acquisition. In conclusion, I will summarize the suggestions for further research discussed in the previous section.
First of all, as I repeatedly mentioned in this paper, a much larger sample size is necessary. Also, a larger number of target words and treatment sentences will make the results more reliable. Second, another pilot study will be needed to investigate the relationship between the length of sentence and the reading time in order to validate the use of mean reading time per word for comparison. Third, a multiple-choice meaning recognition test will, I hope, reflect a certain level of vocabulary acquisition that cannot be measured by the form recognition test or the word translation test. Lastly, the use of nonsense words will eliminate the problem of the participants already knowing some of the target words.
[-- 21 --]
REFERENCES
Baker, E. L., Atwood, N. K., & Duffy, T. M. (1988). Cognitive approaches to assessing the readability. In A. Davidson & G. M. Green (Eds.), Linguistic complexity and text comprehension: Readability issues reconsidered (pp. 55-83). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Blau, E. K. (1982). The effect of syntax on readability for ESL students in Puerto Rico. TESOL Quarterly, 16(4), 517-528.
Bley-Vroman, R., & Masterson, D. (1989). Reaction time as a supplement to grammaticality judgements in the investigation of second language learners' competence. University of Hawai'i Working Papers in ESL, 8(2), 207-237.
Chaudron, C. (1985). Intake: On models and methods for discovering learners' processing of input. Studies in Second Language Acquisition, 7, 1-14.
Chung, H. (1995). Effects of elaborative modification on second language reading comprehension and incidental vocabulary learning. Unpublished master's thesis, University of Hawai'i at Manoa, Honolulu.
Cohen, J., MacWhinney, B., Flatt, M., & Provost, J. (1993). PsyScope: An interactive graphic system for designing and controlling experiments in the psychology laboratory using Macintosh computers. Behavior Research Methods, Instruments, and Computers, 25(2), 257-271.
Dahl, H. (1979). Word frequencies of spoken American English. Essex, CT: Verbatim.
Ferguson, C. A. (1975). Toward a characterization of English foreigner talk. Anthropological Linguistics, 17(1), 1-14.
[-- 22 --]
Freedman, S. E., & Forster, K. I. (1985). The psychological status of overgenerated sentences. Cognition, 19, 101-131.
Green, G. M., & Olsen, M. S. (1988). Preferences for and comprehension of original and readability adapted materials. In A. Davidson & G. M. Green (Eds.), Linguistic complexity and text comprehension: Readability issues reconsidered (pp. 115-140). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Issidorides, D. C., & Hulstijn, J. H. (1992). Comprehension of grammatically modified and nonmodified sentences by second language learners. Applied Psycholinguistics, 13, 147-171.
Kemper, S. (1988). Inferential complexity and the readability of text. In A. Davidson & G. M. Green (Eds.), Linguistic complexity and text comprehension: Readability issues reconsidered (pp. 141-165). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Kim, Y. (1996). Effects of text elaboration on intentional and incidental foreign language vocabulary learning. Unpublished master's thesis, University of Hawai'i at Manoa, Honolulu.
Kleifgen, J. A. (1985). Skilled variation in a kindergarten teacher's use of foreigner talk. In S. M. Gass & C. G. Madden (Eds.), Input in second language acquisition (pp. 59-68). Rowley, MA: Newbury House.
Long, M. H. (1996). The role of the linguistic environment in second language acquisition. In W. C. Ritchie & T. K. Bhatia (Eds.), Handbook of second language acquisition (pp. 413-468). San Diego: Academic Press.
Longman. (1987). Longman dictionary of contemporary English. (2nd ed.). New York: Longman.
Parker, K., & Chaudron, C. (1987). The effects of linguistic simplification and elaborative modifications on L2 comprehension. University of Hawai'i Working Papers in ESL, 6(2), 107-133.
[-- 23 --]
Pica, T., Doughty, C., & Young, R. (1986). Making input comprehensible: Do interactional modifications help? ITL Review of Applied Linguistics, 72, 1-25.
Pica, T., Young, R., &a,p; Doughty, C. (1987). The impact of interaction on comprehension. TESOL Quarterly, 21(4), 737-758.
Watanabe, Y. (1992). Effects of increased processing on incidental learning of foreign language vocabulary. Unpublished master's thesis, University of Hawai'i at Manoa, Honolulu.
Wesche, M. B., & Ready, D. (1985). Foreigner talk in the university classroom. In S. M. Gass & C. G. Madden (Eds.), Input in second language acquisition (pp. 89-114). Rowley, MA: Newbury House.
Yano, Y., Long, M., H., & Ross, S. (1994). The effects of simplified and elaborated texts on foreign language reading comprehension. Language Learning, 44(2), 189-219.
[-- 24 --]
[NOTE] Appendices were not attached to this web document because of the difficulty in converting them into html format.Should you need them, please ask the author for a hardcopy at urano@hawaii.edu. Thank you.
Appendix A. The Participants Bio-data
Appendix B. Test Sentences and Questions
Appendix C. Form Recognition Test
Appendix D. Word Translation Test
[-- 28 --]